훈련시킨 사진 결과
other\n02085936_1325.jpg


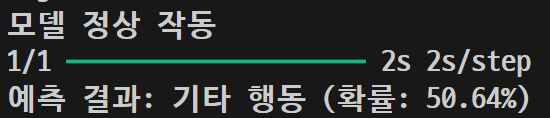
| 이미지 | 5차 결과 | 6차 결과 |
sit\n02086079_186.jpg

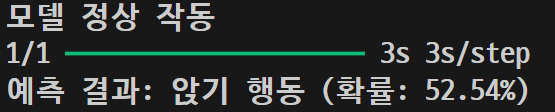
| 이미지 | 5차 결과 | 6차 결과 |
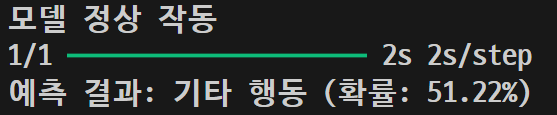
sit\n02087046_4832.jpg


| 이미지 | 5차 결과 | 6차 결과 |
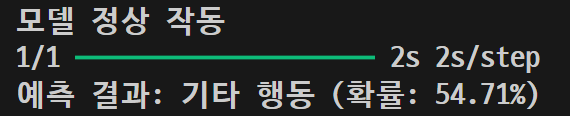
other\n02085620_7440.jpg


![]()
| 이미지 | 5차 결과 | 6차 결과 |
other\n02086240_2705.jpg


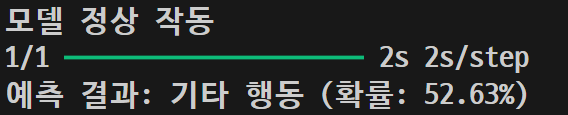
| 이미지 | 5차 결과 | 6차 결과 |
other\n02086646_3052.jpg



| 이미지 | 5차 결과 | 6차 결과 |
4차 테스트 때와 비교하면 확률은 올라가고, sit 행동은 잘 구분하는것처럼 보였으나 기타행동을 구분못함..
아예 잘못된 듯한 느낌 다른 분들 코드를 더 참고 해야할 것 같다..
다시..!
오늘 안에 안되면 바로 openAI로 돌리자 빠른 판단으로 ..!
# 데이터 경로 설정
base_dir = "./data/dogs_vs_cats"
train_dir = r"C:\data\dogs_vs_cats\train"
validation_dir = r"C:\data\dogs_vs_cats\validation"
# 데이터 증강
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode="nearest"
)
validation_datagen = ImageDataGenerator(rescale=1.0 / 255)
# 데이터 로드
train_generator = train_datagen.flow_from_directory(
train_dir, target_size=(150, 150), batch_size=20, class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary'
)
# 모델 구성
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3), padding='same'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu', padding='same'),
MaxPooling2D((2, 2)),
Conv2D(128, (3, 3), activation='relu', padding='same'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
# 모델 요약 출력
model.summary()
# 모델 컴파일
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
# 모델 훈련
history = model.fit(
train_generator,
epochs=10,
validation_data=validation_generator
)
# 정확도 그래프 출력
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
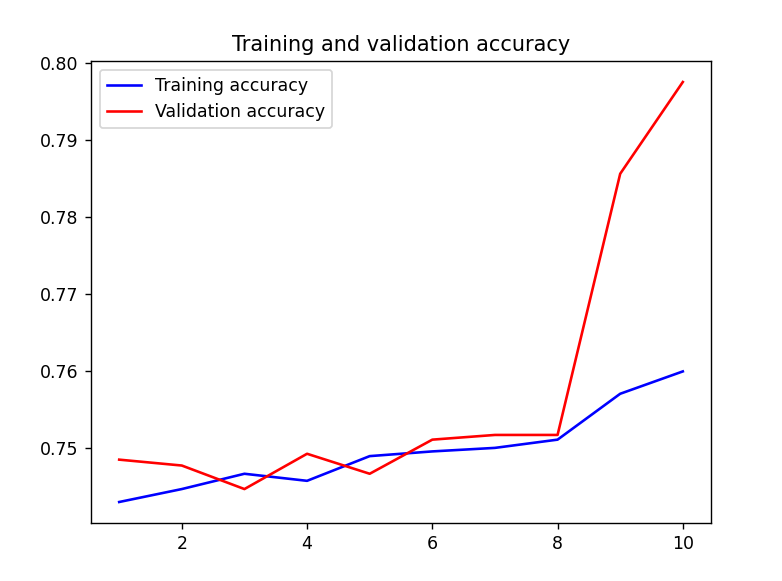
결과 1

위는 훈련 정확도(Training Accuracy)와 검증 정확도(Validation Accuracy)를 나타내는 그래프로 모델 성능의 변화와 과적합 여부를 확인할 수 있다.
푸른색 선은 훈련 정확도, 붉은색 선은 검증 정확도로 훈련보다 더 빠르게 상승하고 있다.
그래프 후반부로 갈수록 검증 정확도가 훈련 정확도보다 더 높은 경우가 나타남
# 데이터 증강
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
rotation_range=40, # 회전 범위를 20 -> 40도로 증가
width_shift_range=0.3, # 수평 이동 범위 증가 (0.2 -> 0.3)
height_shift_range=0.3, # 수직 이동 범위 증가 (0.2 -> 0.3)
shear_range=0.2, # 기울기 조절 범위 증가 (0.1 -> 0.2)
zoom_range=0.2, # 확대/축소 범위 증가 (0.1 -> 0.2)
horizontal_flip=True,
vertical_flip=True, # 수직 뒤집기 추가
fill_mode="nearest"
)
Conv2D(256, (3, 3), activation='relu', padding='same'), # 필터 수를 256으로 증가
MaxPooling2D((2, 2)),결과 2
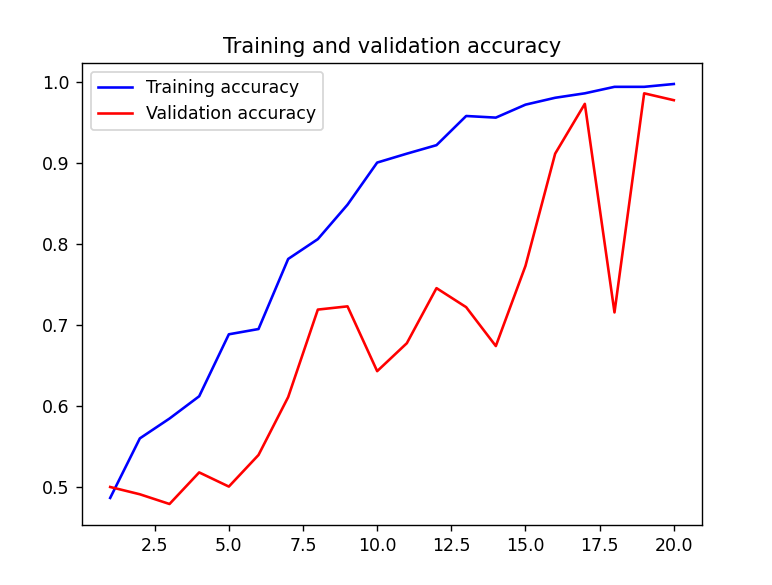
초반 에포크 동안 훈련 정확도와 검증 정확도가 거의 비슷하게 증가하지 않고 0.75 ~ 0.76 사이
8번째 에포크 이후 검증 정확도가 급격하게 상승, 훈련 정확도보다 더 높아짐
결과 3
# 데이터 로드
train_generator = train_datagen.flow_from_directory(
train_dir, target_size=(150, 150), batch_size=20, class_mode='binary', shuffle=True
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary', shuffle=True
)

shuffle true로 설정 후, 이미지 폴더 확인 후 개수가 동일하지 않아...... 동일하게 1000장으로 바꾼 후 실행한 결과.. 저게 뭐지 ....
과소적합(underfitting)이란 과대적합의 반대 개념으로서 머신러닝 모델이 충분히 복잡하지 않아 발생
결과 4
코드에서 ResNet50, OpenVC로 데이터 전처리 / OpenCV로 전처리한 데이터를 TensorFlow 데이터셋에 담아 모델을 학습
그래프를 보면 그동안 나왔던 결과에 비해 훈련 정확도와 검증 정확도가 모두 증가하는 경향을 보이고 있다.
하지만 훈련 정확도가 거의 100%에 도달한 반면, 검증 정확도는 그보다 낮고, 중간에 변동이 크다.. 모델이 훈련 데이터에는 잘 맞지만, 검증 데이터에는 다소 과적합
결과 5
verbose=1
from tensorflow.keras.callbacks import ReduceLROnPlateau
lr_scheduler = ReduceLROnPlateau(
monitor='val_loss', factor=0.5, patience=2, verbose=1
)

상승하고, 급격한 변화는 결과 4에 비해 줄어든 모습..! 개선되고 있는 것 같다
학습률 감소 스케줄러
이상적인 그래프 형태
- 시간이 지남에 따라 두 그래프가 수렴하거나 비슷한 수준을 유지할 때 훈련이 잘 된 상태
- 두 정확도의 차이가 크지 않고, 0.5~3% 내외의 차이일 때
- 훈련 정확도와 검증 정확도가 비슷하게 유지되며 일정 수준 이상에서 그래프가 평탄해지는 것이 좋다.
- 만약 훈련 정확도는 높고 검증 정확도가 낮다면 과적합 발생한 것
'팀프로젝트 - TailsRoute' 카테고리의 다른 글
| TEAM Project (11.02) - 디자인 작업 (0) | 2024.11.02 |
|---|---|
| TEAM Project (10.26) - 정확도 그래프 ( 이미지 분석 완료 ) (0) | 2024.10.26 |
| TEAM Project (10.24) - Epoch, Batch Size, OpenCV( 4차 테스트 ) (0) | 2024.10.24 |
| TEAM Project (10.22) - Epoch(50), OpenCV ( 3차 테스트 ) (1) | 2024.10.23 |
| TEAM Project (10.21) - ResNet50 ( 2차 테스트 ) (2) | 2024.10.21 |

