삽질을 연달아.. 최종최종
- 사용자가 영상을 보내면 관절 데이터를 추출해서 ST-GCN 에 넣는다.
- ST-GCN 훈련 : 내가 가진 CSV 데이터로 ST-GCN을 가르친다.
- 결과
frame_number,frame_path,x1,y1,x3,y2,x5,y3,x7,y4,x9,y5,x11,y6,x13,y7,x15,y8,x17,y9,x19,y10,x21,y11,x23,y12,x25,y13,x27,y14,x29,y15,label
0,data/train/bodylower/frame_bodylower\dog-bodylower-001010\frame_0_timestamp_0.jpg,0.5962962962962963,0.6640625,0.587037037037037,0.45625,0.7,0.5604166666666667,0.6768518518518518,0.6489583333333333,0.5768518518518518,0.271875,0.3555555555555555,0.5359375,0.8203703703703704,0.4427083333333333,0.375,0.6536458333333334,0.8055555555555556,0.5598958333333334,0.3583333333333333,0.2822916666666666,0.8333333333333334,0.2703125,0.3861111111111111,0.6375,0.8046296296296296,0.5583333333333333,0.7287037037037037,0.178125,0.8055555555555556,0.2119791666666666,0
내가 가진 CSV 파일을 ST-GCN 모델을 훈련시킨다.
Skeleton 데이터 (x,y 좌표)와 레이블(label)을 통해 모델은 행동을 학습하고 예측할 수 있음
결론적으로 이 페이지는 강아지 행동 분류를 위한 ST-GCN (Spatio-Temporal Graph Convolutional Network) 모델을 구현하는 데 중점을 둠. 강아지의 관절 위치 (x, y좌표) 데이터를 사용하여 다양한 행동을 분류하는 모델을 훈련시킨다. 이 모델은 비디오 데이터나 연속된 이미지 프레임을 통해 강아지의 움직임을 분석하고, 특정 행동 (ex : 앉기, 누워 있기 등)을 예측할 수 있다.
코드구조
- Config -> 모델 훈련에 필요한 모든 설정을 저장하는 클래스
self.behavior_classes = {
0: '몸 낮추기', # bodylower
1: '몸 긁기', # bodyscratch
2: '몸 흔들기', # bodyshake
3: '앞발 들기', # feetup
4: '한쪽 발 들기', # footup
5: '고개 돌리기', # heading
6: '누워 있기', # lying
7: '마운팅', # mounting
8: '앉아 있기', # sit
9: '꼬리 흔들기', # tailing
10: '돌아보기', # turn
11: '걷거나 뛰기' # walkrun
}- Dataset -> PyTorch의 Dataset을 상속받아, 데이터를 모델에 맞는 형태로 변환
- 각 샘플은 강아지의 관절 좌표 데이터를 포함하여, x와 y 좌표가 joints 수만큼 나열되어있다. 이 데이터는 프레임 수, 관절 수, x/y 좌표의 3D 텐서로 변환된다.
- __getitem__ 메서드는 데이터셋에서 특정 인덱스의 데이터를 반환합니다. 반환되는 데이터는 강아지의 관절 좌표 데이터와 해당 행동에 대한 레이블
- STGCN -> 그래프 합성곱 네트워크, 각 관절을 그래프의 노드로 보고, 관절 간 연결 관계를 그래프의 엣지로 모델링 / 이 네트워크는 공간적 및 시간적 특성을 모두 학습할 수 있도록 설계
- trin_behavior_model.py
-> 모델을 훈련시키는 함수, 각 에포크마다 훈련 손실과 정확도를 계산하고, 검증 데이터에서 평가를 수행
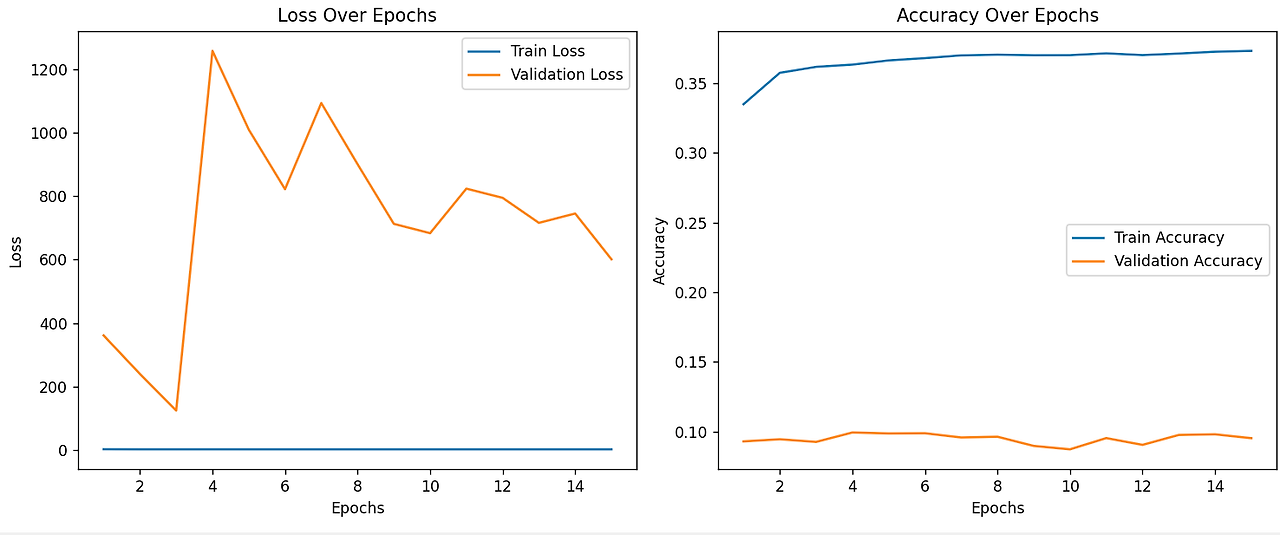


정확도의 최대값은 37%.. 그리고 손실은 1.89
지금까지 나왔던 것중에 정확한 듯.. 영상으로는! 역시 이미지보다 난이도가 더 높은 것 같다..
문제 해결 및 디버깅
데이터셋 불일치 문제
CSV 파일에 있는 관절 좌표 열 이름과 모델이 원하는 형식이 맞지 않아 계속 에러 발생..
csv 파일에서 관절 좌표는 강아지의 15개 관절에 대한 x, y좌표가 있어야하고, 이 데이터를 csv파일에서 어떻게 추출?
x1,y1,x3,y2,x5,y3,x7,y4,x9,y5,x11,y6,x13,y7,x15,y8,x17,y9,x19,y10,x21,y11,x23,y12,x25,y13,x27,y14,x29,y15 강아지의 15개의 관절에 대한 2D 좌표, 이 데이터는 총 30개의 열이 필요
joint_columns 정의하기
데이터를 모델이 이해할 수 있게 처리해야하는데, 15개의 관절에 대해 열의 이름을 self.joint_columns로 정의
CSV 파일에 있는 관절 좌표 열이 코드에서 정의한 joint_columns과 정확히 일치해야한다. ( -> 당연히 1~15 순으로 되어있는 줄 알고 순서대로 작성했다가 확인해보니, 순서대로 적혀 있지 않았음.. 역시.. 예측은 좋지않아.. 다 꼼꼼히 확인해야지..)
fc 계층의 입력 텐서 크기와 선형 계층의 가중치 크기가 일치하지 않아서 에러 발생
RuntimeError: mat1 and mat2 shapes cannot be multiplied (16x115200 and 192000x12)선형 계층(fc)에 입력되는 텐서 크기와 선형 계층의 가중치 크기가 맞지 않아서 발생하는 에러
이게 뭔 소리지..
mat1의 크기: (16, 115200) → 배치 크기 16, 피처 크기 115200
mat2의 크기: (192000, 12) → 선형 계층의 가중치 크기
이 문제는 모델에서 Conv 계층을 거친 후에 나온 출력 텐서를 평탄화해서 선형 계층에 넣는데 이때 계산 방식이 잘못 된 것
선형 계층은 사실 2D 텐서만 처리, 텐서라는 건 데이터가 여러 차원으로 배열된 걸 말하는데, 선형 계층에서는 이런 배열을 2D 배열로 바꿔줘야한다더라..
(배치 크기, 피처 크기) 형태로 바꿔야 한다는 거지. 그래서 x = x.view(x.size(0), -1) 이걸 사용
배치 크기를 제외한 나머지 차원을 자동으로 계산해서 평탄화해주는 역할
내가 겪은 문제는 Conv 계층에서 나오는 출력 크기와 fc 계층의 입력 크기를 계산하는 방식이 맞지 않아서 발생
모델 설계에서, Conv 계층을 통과하고 나면 출력 텐서의 크기가 (batch_size, channels, frames, joints) 이런 형태로 나오는데, (16, 256, 30, 15)라면, 이걸 평탄화해서 256 30 15 = 115200 이렇게 2D로 바꿔줘야... 한다더라..
그래서 어떻게 해결?
텐서의 크기를 맞추기 위해서는 Conv 계층에서 나오는 텐서 크기를 정확하게 계산하고, 그에 맞춰 fc 계층의 입력 크기를 설정해야된다...!!
'팀프로젝트 - TailsRoute' 카테고리의 다른 글
| TEAM Project (11.30) (0) | 2024.12.01 |
|---|---|
| TEAM Project (11.29) - SAMURAI 적용 (0) | 2024.11.30 |
| TEAM Project (11.26) (0) | 2024.11.26 |
| TEAM Project (11.25) - 카카오 소셜 로그인 구현 (0) | 2024.11.25 |
| TEAM Project(11.23) - 회원가입 시 이메일 인증 (0) | 2024.11.24 |


