Epoch(50), 100개 레이어 고정
-> 결과 : 블루 스크린 뜸.. ㅎ
과하게 돌렸던걸로.. 어쩐지 컴퓨터가.. 시끄럽더라.. 하하
EarlyStopping 콜백을 사용
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss',
patience=10,
restore_weights=True
)
history = model.fit(
train_generator,
validation_data=val_generator,
epochs=50, # 최대 에폭 수
callbacks=[early_stopping]
)
에폭 수를 줄이고, EarlyStopping 콜백을 사용하여 모델이 더 이상 개선되지 않을 때 학습을 조기 종료할 수 있도록 하자
계속 테스트 하면서 시간도 체크하고, 결과물을 보고 에폭 수와 뉴런 수를 조절해야할 듯
epoch
에폭은 모델이 데이터를 몇 번 반복해서 학습할지
뉴런 수
현재는 Dense(512)인데 이처럼 층에 있는 뉴런 수가 많아지면 더 복잡한 패턴을 학습할 수 있다. 하지만 너무 많은 뉴런은 필요 이상으로 데이터를 학습하기에(과적합) 문제가 생길 수 있기에 조절 필요 그리고 학습 속도도 느려지고 계산 자원이 많이 필요함
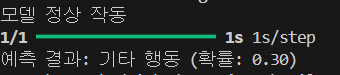
epoch, 뉴런 수를 20, 216 으로 내려도 계속 블루스크린... 그래서 일단 epoch 수를 블루스크린 뜨기 전.. 10으로 뉴런 수를 216으로 설정하고 훈련 시킨 결과 ( 컴퓨터 소리도 커지고.. 또 블루스크린 뜰까봐 무서웠음.. 노트북에서는 실행 못 시킬 듯 다른 방법 찾아야 될 것 같음 ) 시간은 20분 정도 걸림
훈련시킨 사진 결과
other\n02085936_1325.jpg


sit\n02086079_186.jpg


sit\n02087046_4832.jpg

other\n02085620_7440.jpg

외부사진
dog-6240043_1280.jpg




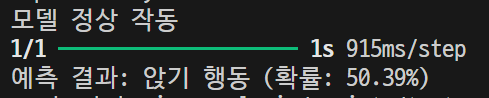
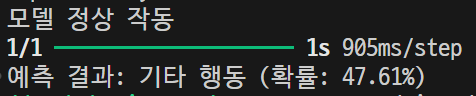
외부사진 몇장 더 가지고 테스트를 해보아야겠지만.. 훈련시킨 사진으로는 이제 그래도 결과가 나오는 것처럼 보였으나 외부 사진을 보냈을 때 또 이상한 결과가 나옴.. 흑백에다가 하얘서 못알아보는건가..
.
.
.
아예 훈련시킨 이미지 외에는 제대로된 결과물을 가져오지 못하는 것 같다. 음... 방식을 추가해야할 듯
'팀프로젝트 - TailsRoute' 카테고리의 다른 글
| TEAM Project (10.25) - OpenCV 흑백 변환, 가우시안 블러(5차, 6차 테스트) (1) | 2024.10.25 |
|---|---|
| TEAM Project (10.24) - Epoch, Batch Size, OpenCV( 4차 테스트 ) (0) | 2024.10.24 |
| TEAM Project (10.21) - ResNet50 ( 2차 테스트 ) (2) | 2024.10.21 |
| TEAM Project (10.18) - Google Drive 연동(대용량 사진, 영상) (0) | 2024.10.18 |
| TEAM Project (10.17) - Stanford Dogs Dataset (2) (1) | 2024.10.17 |