진짜 최종최종최종
SAMURAI 기반 데이터 전처리 및 학습 정확도 향상 계획
SAMURAI를 활용하여 데이터 전처리 단계에서 불필요한 배경 데이터를 제거하고 모델 학습의 정확도를 높이기 목표
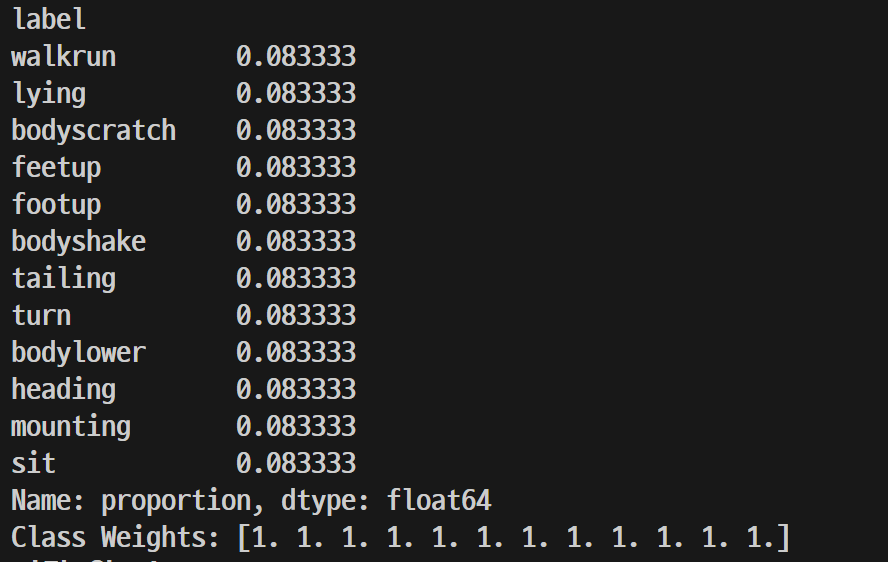
초기 데이터 구조
- 12개 행동, 각 행동당 86개 폴더
- 각 폴더에는 약 13장의 프레임 이미지와 해당 키포인트를 나타내는 JSON 파일 포함
SAMURAI를 활용한 데이터 전처리
데이터셋의 품질 개선을 목적
- 강아지 객체 탐지
SAMURAI 모델 사용
- 각 프레임 이미지에서 강아지 영역을 탐지
- 탐지된 강아지 영역의 경계 상자 (bounding box)를 얻음
- 강아지 영역 크롭
- 탐지된 경계 상자를 기준으로 이미지를 크롭하여 강아지 영역만 남김
- 배경 데이터와 잡음을 제거하여 학습 데이터의 품질을 개선
- 키포인트 조정
- 크롭된 이미지의 좌표계를 기준으로 JSON 파일의 키포인트를 변환
- 강아지 객체의 상대적 위치를 유지하도록 수정
- CSV 데이터 생성
- 크롭된 강아지 영역과 수정된 키포인트 데이터를 새로운 CSV로 기록
- 최종 CSV는 모델 학습에 사용될 고품질 데이터를 포함
학습 데이터 준비
- 데이터셋 변환
- 크롭된 강아지 영역 이미지를 기반으로 행동 라벨과 키포인트 데이터를 결합
- CSV 파일을 읽어 스켈레톤 데이터와 라벨로 변환
추가할까
데이터 증강
- 영상 데이터 증강 : 이미지 변환 (회전, 크기 조절, 밝기 및 색상 변화), 시간적 증강(영상에서 프레임을 무작위로 선택하거나 순서를 변경하여 모델이 시간적 패턴에 더 강건하도록)
- 스켈레톤 데이터 증강 : 키포인트 데이터를 변형하거나 노이즈를 추가하여 스켈레톤 기반 모델의 일반화 성능을 높일 수 있음
- 데이터 로더 생성
- PyTorch DataLoader를 사용해 데이터를 배치 단위로 처리
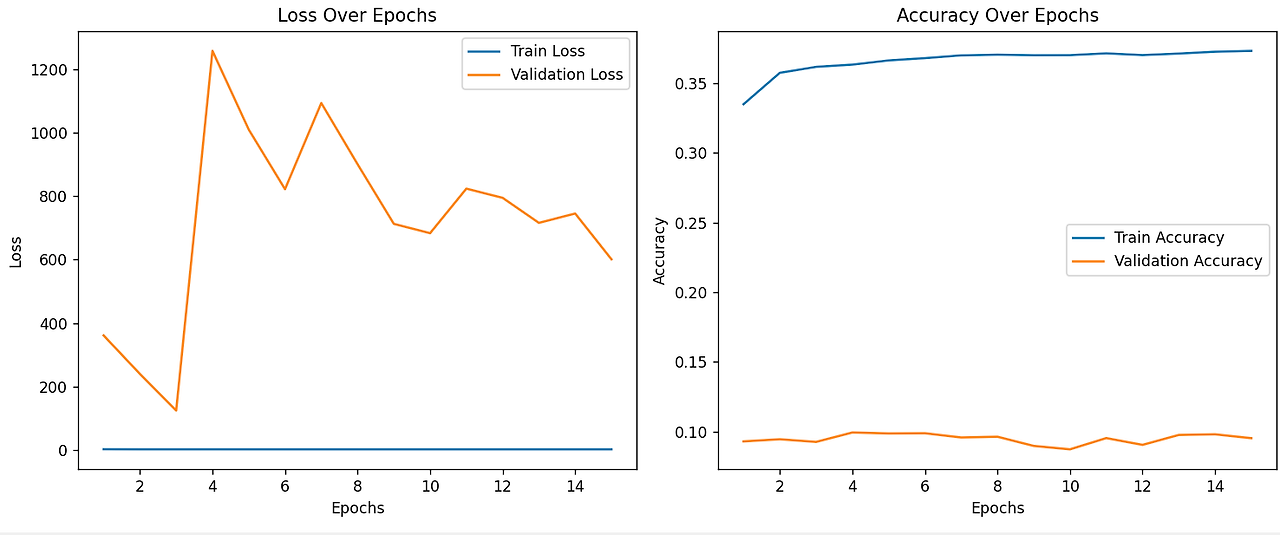
모델 훈련
- ST-GCN + SAMURAI-like 3D CNN의 통합 학습
- SAMURAI-like 3D CNN은 추가적인 특징 추출 단계, 공간적-시간적 행동 패턴을 더욱 복잡하고 정교하게 학습
- ST-GCN이 학습한 특징 (스켈레톤 데이터 기반)과 SAMURAI-like 3D CNN이 학습한 특징 (이미지 기반)을 융합하여 더 정확하고 강력한 예측이 가능
- ST-GCN은 스켈레톤 데이터를 활용한 행동 분석에 뛰어난 성능을 보이지만, 이미지에서 강아지의 전체적인 역동적 움직임을 학습하는 데는 제한적
- SAMURAI-like 3D CNN은 원본 이미지에서 동적 특징을 학습, 이는 ST-GCN과 상호보완적인 역할
두 모델의 출력을 융합 계층(Fusion Layer)에서 결합하면, 각 모델의 장점을 모두 활용할 수 있다.
- ST-GCN : 스켈레톤 기반 공간적-시간적 특징 학습
- SAMURAI-like 3D CNN : 이미지 기반 동적 패턴 학습
이렇게 학습된 모델은 영상 데이터를 프레임 단위로 처리하여 각 프레임 (또는 연속된 프레임의 시퀀스)에서 강아지의 행동을 예측한다.
한계
SAM 2.1로 시도했는데, 계속 아래와 같은 에러발생
initialize_and_load_sam_model
model_path = cfg.sam_model_path
omegaconf.errors.ConfigAttributeError: Key 'sam_model_path' is not in struct
full_key: sam_model_path
object_type=dict
Set the environment variable HYDRA_FULL_ERROR=1 for a complete stack trace.
ConfigCompositionException 오류는 Hydra가 YAML 설정 파일을 파싱하거나 컴포지션(구성)을 할 때 문제가 생겼을 때 발생
.
.
.
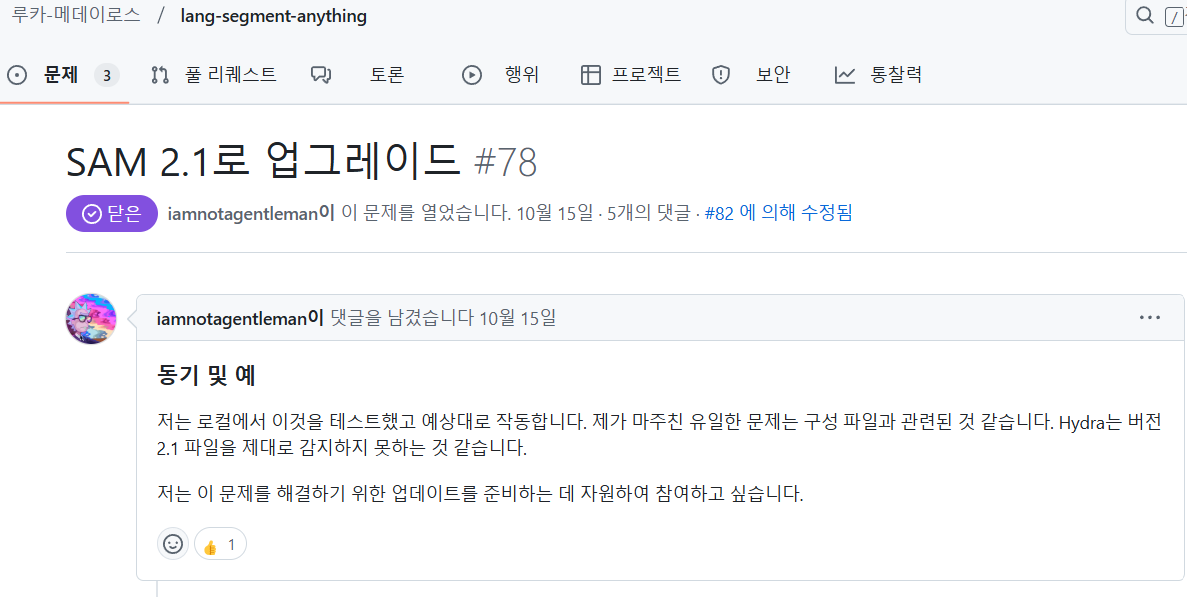
아무리해도 고쳐지지 않아서 github issue를 확인해보니.. issue에 2.1은 감지를 제대로 하지 못한다는 나와 비슷한 경우의 문제를 발견... SAM2 로 사용..?
.
.
.
RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from http://www.nvidia.com/Download/index.aspx
PyTorch는 주로 NVIDIA CUDA를 기반으로 하며, AMD GPU의 경우 기본적으로 지원되지 않습니다
SAM-2는 CUDA 확장을 사용하는 것으로 보이며, NVIDIA GPU에서만 CUDA를 사용할 수 있습니다. AMD GPU는 CUDA를 지원하지 않기 때문에, SAM-2의 일부 기능은 사용할 수 없을 가능성이 큽니다.
CUDA를 비활성화하고 CPU에서 실행, OpenCL이나 ROCm 기반의 설정을 고려, ROCm은 Linux 환경으로 전환해야한다고 해서 패스, OpenCL 사용하려고 했는데... 이것도 마찬가지
CPU에서 실행하려면, 코드에서 명시적으로 device를 CPU로 설정해야 합니다
device = torch.device("cpu")
sam_model.to(device)
강제로 cpu로 시도하려고 하였으나
기능을 사용하려면 CUDA 버전과 GPU 아키텍처가 적합해야 하는데, 현재 환경에서는 사용할 수 없다는 내용이 계속 발견..
.
.
.
samurai가 nvidia 에서 훈련시킨걸로 나의 그래픽카드로는 계속 안된다고 떠.... 서 ..... 학원 컴퓨터에서 해야할 거 같은데.. 시간이 되려나...............
'팀프로젝트 - TailsRoute' 카테고리의 다른 글
| TEAM Projcet - YOLOv7을 이용한 객체 감지 (0) | 2024.12.05 |
|---|---|
| TEAM Project (12.02) - 데이터 전처리 (SAMURAI 적용, 데이터 양 조절) (0) | 2024.12.03 |
| TEAM Project (12.01) - SAMURAI, SAM 2 설치 (0) | 2024.12.02 |
| TEAM Project (11.30) (0) | 2024.12.01 |
| TEAM Project (11.29) - SAMURAI 적용 (0) | 2024.11.30 |